Last edited: Nov 13, 2015, 11:16pm -0600
Research log: cell states and microarrays
Context
I guess I should lay out some context since I never update this anymore.
The news about my life is that I’m a graduate student at the University of Utah again, working on a PhD, albeit part time. I’ve been on leave from the grad program for so long and my leave request justifications were getting so tortured that I decided I should probably just go back before I get kicked out. We’re out of our minds over at Space Monkey and I’m staying on there part time as Director of Engineering too!
Anyways, two days a week I am up in a cancer research lab. Surprise! Turns out when you have cool advisors who start crossing into new fields you might get lucky and get to follow them around. My due progress forms now say that I will attempt to find a novel and scalable way to discover targeted therapeutics for genetic disorders instead of whatever they used to say. I’m not sure the forms actually say attempt but that specific word choice is key.
To say my statement of focus another way, using lots of data about cell behavior, I’m going to try and predict if the effects or side-effects of already FDA-approved drugs can potentially help people with rare diseases, who in-and-of themselves don’t constitute a pharmaceutical market. Maybe we can help some people! I’m in a cancer research lab because cancer research has a lot of similar problems (and solutions!).
Instead of filling up @utah.edu inboxes of the current situation going on in my research folder, I’ve decided to write about it here instead. In addition, I’m a firm believer that explaining things helps you better understand them, and after noodling all day Tuesday on a problem, I decided I really ought to rubber duck to you, dear reader.
So that’s what’s going on.
Just because I don’t want to start all the way from the bottom, I’m going to assume you’ve taken some Biology 101 class and understand what I think is hilariously still referred to as the central dogma of molecular biology. I’ll try to briefly recap the important points. (Aside: It’s so encouraging when science icons do dumb things like assume the wrong definition of a word and then no one fixes it. There’s hope for me yet is what I’m saying.)
If you found this page by Googling or don’t know me or something, this is a pretty large shift in focus for me. I am a computer science/software development guy, and have had exactly zero training in biology or any other like-science. Prior to this, I read some books once and did pretty alright in high school.
Basically what I’m saying is that I have no idea what I’m doing, caveat emptor, etc., etc.
For this entry I’m going to cover cell states and microarrays as background for what I’m actually doing, which will come in a subsequent post.
End context.
Cell states
Cells, of course, have DNA, which is basically the cell construction blueprint. DNA is made up of long strands of base pairs (A, T, G, or C). Every cell in an organism has the same DNA and thus the same blueprints, but obviously not every cell behaves the same, looks the same, does the same things, etc. Elbow cells are usually pretty different from brain cells, though if they aren’t you might want to get that checked out.
Summary: all cells have the same DNA but behave differently!
The thing that’s different between your elbow cell and your brain cell is what genes are being expressed. The word gene itself doesn’t seem to actually have a consistently used concrete definition (ask a biologist if a gene is defined pre- or post- intron splicing!), but in general, a gene is roughly the atomic unit of a trait, or, what causes your elbow cells to be different than your brain cells. The part of a DNA strand that represents a specific gene, when activated, will be turned into RNA which is then turned into proteins. So when I say expressed or gene expression, I mean that a specific subsequence of DNA is actively getting turned into RNA and then into proteins.
Summary: cells behave differently because only some genes are being made into proteins in each cell!
It turns out that because all of this evolved over long time periods from molecules just bouncing around, the inner-workings of any cell are a haphazard nightmare of chaos. Long, complicated Rube Goldberg-esque contraptions all operate in harmony to allow you to even wonder if life really has any meaning. Often, all a gene will do is generate a protein that will activate another section of DNA. As a result, cells have these cascading feedback loops of proteins that activate genes that activate other proteins that interact with a hormone that activates a protein that activate genes that activate other proteins that then finally kick a domino over or make more KRAS or something.
Summary: genes get turned off and on via complex but haphazard processes!
These long chains of gene regulatory protein interactions are called pathways, and as you might imagine, being able to know which gene expression pathways are active in a cell is a very useful way to figure out what a cell is doing or what state that cell is in. For example: is this cell a brain cell? If it has a lot of the same RNA being expressed as an elbow cell and not a lot of the same RNA being expressed as a brain cell then probably not!
For a concrete example of a pathway, here’s a diagram illustrating the interaction between the Wnt and insulin signaling pathways, courtesy of Yoon JC, Ng A, Kim BH, Bianco A, Xavier RJ, and Elledge SJ, CC BY-SA 3.0:
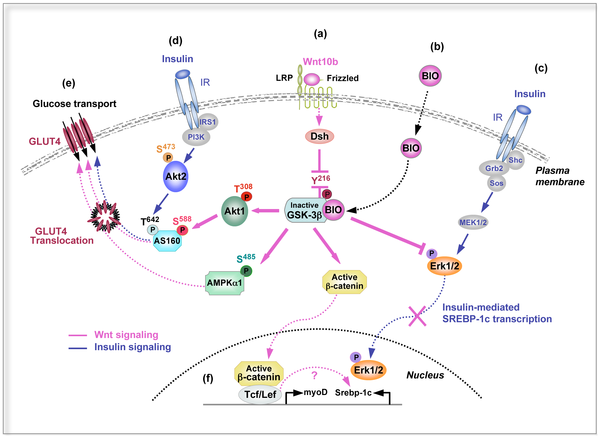
Summary: figuring out what genes are turned on could help identify what a cell is doing!
A brief comment about DNA sequencing, or the Human Genome Project, or similar efforts: for all the popular interest and excitement DNA sequencing gets (or, determining what the base pairs are that the DNA is made up of), we still don’t know enough to decipher what that DNA actually means. Imagine you and your friend Craig Venter are racing to be the first to get the latest installment of A Song of Ice and Fire, but the bearded author wrote it in Tagalog and you don’t speak Tagalog and you’re not even sure if Austronesia is even a place. What good does this book you just bought do you if you can’t understand it? Sequencing a cell’s DNA will not tell you how to understand what that cell is currently doing, especially when the DNA is the same for all of that organism’s cells.
But, measuring the amount of different kinds of RNA (or proteins) will easily give you clues as to what the cell is doing relative to other cells, even if you don’t know what the RNA means! Measuring which specific proteins exist is a hard problem, but luckily, measuring different amounts of RNA is one of the things molecular biologist are best at! Yay!
{kind=link}
Summary: Measuring RNA amounts in a cell tells us what genes are active!
Microarrays
Most of the data I’ve been working with has been generated from microarray technology.
When RNA is transcribed from DNA, the RNA base pairs bond to the DNA strand and are then essentially glued together, so that when the RNA is unzipped off the DNA, the RNA is in the right complementary order. What this means is that any specific RNA strand will bond with specific complementary strands of DNA. This is the key microarray observation.
Without going into the gory details, it turns out that we can do two useful things. First, we can actually make arbitrary synthetic DNA strands in the lab, and second, we can exponentially increase the amount of DNA or RNA through PCR.
A microarray is simply a large number of wells where some small, synthetic strands of DNA are chemically bonded to the bottom of the well. These synthetic strands are called probes. At the bottom of each well is a very specific, chosen probe. If you use PCR to proportionally increase the amount of RNA you have from a cell, you can pour all that RNA into all the wells, let it sit for a bit, and then wash it all out. What happens is the RNA that was most expressed is most likely to have bonded to all the probes at the bottom of the wells and stayed through the wash cycle.
Great, now all we need is a way to measure how much RNA bonded to probes in each well. It turns out, if you use a fluorescent dye or duplicate your RNA using radioactive base pair isotopes, you can now measure just how much RNA bonded in each well based on the light emitted from the well, and therefore, how much of a particular RNA sequence was proportionally in a cell’s expression! Whapah!
As cool as this is, there’s lots of room here for experimental error. This is no way to collect exact data. The data you get back will be very messy, have lots of noise, weird batch affects (like, the current temperature affects bonding!), etc. In fact, since the C-G bond is stronger than the A-T/U bond (it has 3 chemical bonds instead of 2), you’ll see more of probes that have C/G base pairs in them.
Better technology exists. RNA-Seq is almost universally better in every way, except for perhaps cost to some degree. Nonetheless, the older microarray technology is the currently dominant source of this kind of data.
Summary: microarrays let us measure how much RNA there is in a cell!
Whew
Okay, so next time we’ll talk about where this all gets me in terms of finding drugs for people with rare genetic diseases.
Please let me know what questions you have and I promise to give you a good show while I stumble around trying to answer them!
Update: a previous version of this entry claimed that “epigenetics” was the name of the study of all forms of gene expression regulation, whereas in actuality it is only the study of external or environmental factors for gene expression regulation. I attempted to fix rather than remove the comment about epigenetics, but it then seemed to distract from the point I was trying to make, so for better or worse the tangent will have to wait for perhaps a later entry. Sorry to have misled!